mirror of
https://github.com/fmtlib/fmt.git
synced 2026-06-15 08:26:13 +08:00
docs(readme): document usage of fmt as a C++20 module (#4237)
This commit is contained in:
parent
2f18a88e68
commit
0e840f8c62
496
README.md
496
README.md
@ -1,493 +1,15 @@
|
|||||||
<img src="https://user-images.githubusercontent.com/576385/156254208-f5b743a9-88cf-439d-b0c0-923d53e8d551.png" alt="{fmt}" width="25%"/>
|
# {fmt}
|
||||||
|
|
||||||
[](
|
[](https://github.com/fmtlib/fmt/actions/workflows/build.yml)
|
||||||
https://github.com/fmtlib/fmt/actions?query=workflow%3Alinux)
|
[](https://fmt.dev/)
|
||||||
[](
|
|
||||||
https://github.com/fmtlib/fmt/actions?query=workflow%3Amacos)
|
|
||||||
[](
|
|
||||||
https://github.com/fmtlib/fmt/actions?query=workflow%3Awindows)
|
|
||||||
[](
|
|
||||||
https://issues.oss-fuzz.com/issues?q=title:fmt%20cc:victor.zverovich@gmail.com)
|
|
||||||
[](
|
|
||||||
https://www.bestpractices.dev/projects/8880)
|
|
||||||
[](
|
|
||||||
https://securityscorecards.dev/viewer/?uri=github.com/fmtlib/fmt)
|
|
||||||
[](https://stackoverflow.com/questions/tagged/fmt)
|
|
||||||
|
|
||||||
**{fmt}** is an open-source formatting library providing a fast and safe
|
{fmt} is an open-source formatting library providing a fast and safe alternative to C stdio and C++ iostreams.
|
||||||
alternative to C stdio and C++ iostreams.
|
|
||||||
|
|
||||||
If you like this project, please consider donating to one of the funds
|
## Using {fmt} as a C++20 Module
|
||||||
that help victims of the war in Ukraine: <https://u24.gov.ua/>.
|
|
||||||
|
|
||||||
[Documentation](https://fmt.dev)
|
To use {fmt} as a C++20 module, ensure your project is configured with C++20 or later and that your compiler supports modules (e.g., GCC 14+, Clang 16+, or MSVC 19.34+).
|
||||||
|
|
||||||
[Cheat Sheets](https://hackingcpp.com/cpp/libs/fmt.html)
|
### CMake Configuration
|
||||||
|
The recommended way to use {fmt} is via the provided CMake target. Do not wrap the library in your own module; use the one provided by the build system.
|
||||||
|
|
||||||
Q&A: ask questions on [StackOverflow with the tag
|
1. Enable module scanning in your `CMakeLists.txt`:
|
||||||
fmt](https://stackoverflow.com/questions/tagged/fmt).
|
|
||||||
|
|
||||||
Try {fmt} in [Compiler Explorer](https://godbolt.org/z/8Mx1EW73v).
|
|
||||||
|
|
||||||
# Features
|
|
||||||
|
|
||||||
- Simple [format API](https://fmt.dev/latest/api/) with positional
|
|
||||||
arguments for localization
|
|
||||||
- Implementation of [C++20
|
|
||||||
std::format](https://en.cppreference.com/w/cpp/utility/format) and
|
|
||||||
[C++23 std::print](https://en.cppreference.com/w/cpp/io/print)
|
|
||||||
- [Format string syntax](https://fmt.dev/latest/syntax/) similar
|
|
||||||
to Python\'s
|
|
||||||
[format](https://docs.python.org/3/library/stdtypes.html#str.format)
|
|
||||||
- Fast IEEE 754 floating-point formatter with correct rounding,
|
|
||||||
shortness and round-trip guarantees using the
|
|
||||||
[Dragonbox](https://github.com/jk-jeon/dragonbox) algorithm
|
|
||||||
- Portable Unicode support
|
|
||||||
- Safe [printf
|
|
||||||
implementation](https://fmt.dev/latest/api/#printf-api)
|
|
||||||
including the POSIX extension for positional arguments
|
|
||||||
- Extensibility: [support for user-defined
|
|
||||||
types](https://fmt.dev/latest/api/#formatting-user-defined-types)
|
|
||||||
- High performance: faster than common standard library
|
|
||||||
implementations of `(s)printf`, iostreams, `to_string` and
|
|
||||||
`to_chars`, see [Speed tests](#speed-tests) and [Converting a
|
|
||||||
hundred million integers to strings per
|
|
||||||
second](http://www.zverovich.net/2020/06/13/fast-int-to-string-revisited.html)
|
|
||||||
- Small code size both in terms of source code with the minimum
|
|
||||||
configuration consisting of just three files, `base.h`, `format.h`
|
|
||||||
and `format-inl.h`, and compiled code; see [Compile time and code
|
|
||||||
bloat](#compile-time-and-code-bloat)
|
|
||||||
- Reliability: the library has an extensive set of
|
|
||||||
[tests](https://github.com/fmtlib/fmt/tree/master/test) and is
|
|
||||||
[continuously fuzzed](https://bugs.chromium.org/p/oss-fuzz/issues/list?colspec=ID%20Type%20Component%20Status%20Proj%20Reported%20Owner%20Summary&q=proj%3Dfmt&can=1)
|
|
||||||
- Safety: the library is fully type-safe, errors in format strings can
|
|
||||||
be reported at compile time, automatic memory management prevents
|
|
||||||
buffer overflow errors
|
|
||||||
- Ease of use: small self-contained code base, no external
|
|
||||||
dependencies, permissive MIT
|
|
||||||
[license](https://github.com/fmtlib/fmt/blob/master/LICENSE)
|
|
||||||
- [Portability](https://fmt.dev/latest/#portability) with
|
|
||||||
consistent output across platforms and support for older compilers
|
|
||||||
- Clean warning-free codebase even on high warning levels such as
|
|
||||||
`-Wall -Wextra -pedantic`
|
|
||||||
- Locale independence by default
|
|
||||||
- Optional header-only configuration enabled with the
|
|
||||||
`FMT_HEADER_ONLY` macro
|
|
||||||
|
|
||||||
See the [documentation](https://fmt.dev) for more details.
|
|
||||||
|
|
||||||
# Examples
|
|
||||||
|
|
||||||
**Print to stdout** ([run](https://godbolt.org/z/Tevcjh))
|
|
||||||
|
|
||||||
``` c++
|
|
||||||
#include <fmt/base.h>
|
|
||||||
|
|
||||||
int main() {
|
|
||||||
fmt::print("Hello, world!\n");
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
**Format a string** ([run](https://godbolt.org/z/oK8h33))
|
|
||||||
|
|
||||||
``` c++
|
|
||||||
std::string s = fmt::format("The answer is {}.", 42);
|
|
||||||
// s == "The answer is 42."
|
|
||||||
```
|
|
||||||
|
|
||||||
**Format a string using positional arguments**
|
|
||||||
([run](https://godbolt.org/z/Yn7Txe))
|
|
||||||
|
|
||||||
``` c++
|
|
||||||
std::string s = fmt::format("I'd rather be {1} than {0}.", "right", "happy");
|
|
||||||
// s == "I'd rather be happy than right."
|
|
||||||
```
|
|
||||||
|
|
||||||
**Print dates and times** ([run](https://godbolt.org/z/c31ExdY3W))
|
|
||||||
|
|
||||||
``` c++
|
|
||||||
#include <fmt/chrono.h>
|
|
||||||
|
|
||||||
int main() {
|
|
||||||
auto now = std::chrono::system_clock::now();
|
|
||||||
fmt::print("Date and time: {}\n", now);
|
|
||||||
fmt::print("Time: {:%H:%M}\n", now);
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Output:
|
|
||||||
|
|
||||||
Date and time: 2023-12-26 19:10:31.557195597
|
|
||||||
Time: 19:10
|
|
||||||
|
|
||||||
**Print a container** ([run](https://godbolt.org/z/MxM1YqjE7))
|
|
||||||
|
|
||||||
``` c++
|
|
||||||
#include <vector>
|
|
||||||
#include <fmt/ranges.h>
|
|
||||||
|
|
||||||
int main() {
|
|
||||||
std::vector<int> v = {1, 2, 3};
|
|
||||||
fmt::print("{}\n", v);
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Output:
|
|
||||||
|
|
||||||
[1, 2, 3]
|
|
||||||
|
|
||||||
**Check a format string at compile time**
|
|
||||||
|
|
||||||
``` c++
|
|
||||||
std::string s = fmt::format("{:d}", "I am not a number");
|
|
||||||
```
|
|
||||||
|
|
||||||
This gives a compile-time error in C++20 because `d` is an invalid
|
|
||||||
format specifier for a string.
|
|
||||||
|
|
||||||
**Write a file from a single thread**
|
|
||||||
|
|
||||||
``` c++
|
|
||||||
#include <fmt/os.h>
|
|
||||||
|
|
||||||
int main() {
|
|
||||||
auto out = fmt::output_file("guide.txt");
|
|
||||||
out.print("Don't {}", "Panic");
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
This can be [up to 9 times faster than `fprintf`](
|
|
||||||
http://www.zverovich.net/2020/08/04/optimal-file-buffer-size.html).
|
|
||||||
|
|
||||||
**Print with colors and text styles**
|
|
||||||
|
|
||||||
``` c++
|
|
||||||
#include <fmt/color.h>
|
|
||||||
|
|
||||||
int main() {
|
|
||||||
fmt::print(fg(fmt::color::crimson) | fmt::emphasis::bold,
|
|
||||||
"Hello, {}!\n", "world");
|
|
||||||
fmt::print(fg(fmt::color::floral_white) | bg(fmt::color::slate_gray) |
|
|
||||||
fmt::emphasis::underline, "Olá, {}!\n", "Mundo");
|
|
||||||
fmt::print(fg(fmt::color::steel_blue) | fmt::emphasis::italic,
|
|
||||||
"你好{}!\n", "世界");
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Output on a modern terminal with Unicode support:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
# Benchmarks
|
|
||||||
|
|
||||||
## Speed tests
|
|
||||||
|
|
||||||
| Library | Method | Run Time, s |
|
|
||||||
|-------------------|---------------|-------------|
|
|
||||||
| libc | printf | 0.66 |
|
|
||||||
| libc++ | std::ostream | 1.63 |
|
|
||||||
| {fmt} 12.1 | fmt::print | 0.44 |
|
|
||||||
| Boost Format 1.88 | boost::format | 3.89 |
|
|
||||||
| Folly Format | folly::format | 1.28 |
|
|
||||||
|
|
||||||
{fmt} is the fastest of the benchmarked methods, \~50% faster than
|
|
||||||
`printf`.
|
|
||||||
|
|
||||||
The above results were generated by building `tinyformat_test.cpp` on
|
|
||||||
macOS 15.6.1 with `clang++ -O3 -DNDEBUG -DSPEED_TEST -DHAVE_FORMAT`, and
|
|
||||||
taking the best of three runs. In the test, the format string
|
|
||||||
`"%0.10f:%04d:%+g:%s:%p:%c:%%\n"` or equivalent is filled 2,000,000
|
|
||||||
times with output sent to `/dev/null`; for further details refer to the
|
|
||||||
[source](https://github.com/fmtlib/format-benchmark/blob/master/src/tinyformat-test.cc).
|
|
||||||
|
|
||||||
{fmt} is up to 20-30x faster than `std::ostringstream` and `sprintf` on
|
|
||||||
IEEE754 `float` and `double` formatting
|
|
||||||
([dtoa-benchmark](https://github.com/fmtlib/dtoa-benchmark)) and faster
|
|
||||||
than [double-conversion](https://github.com/google/double-conversion)
|
|
||||||
and [ryu](https://github.com/ulfjack/ryu):
|
|
||||||
|
|
||||||
[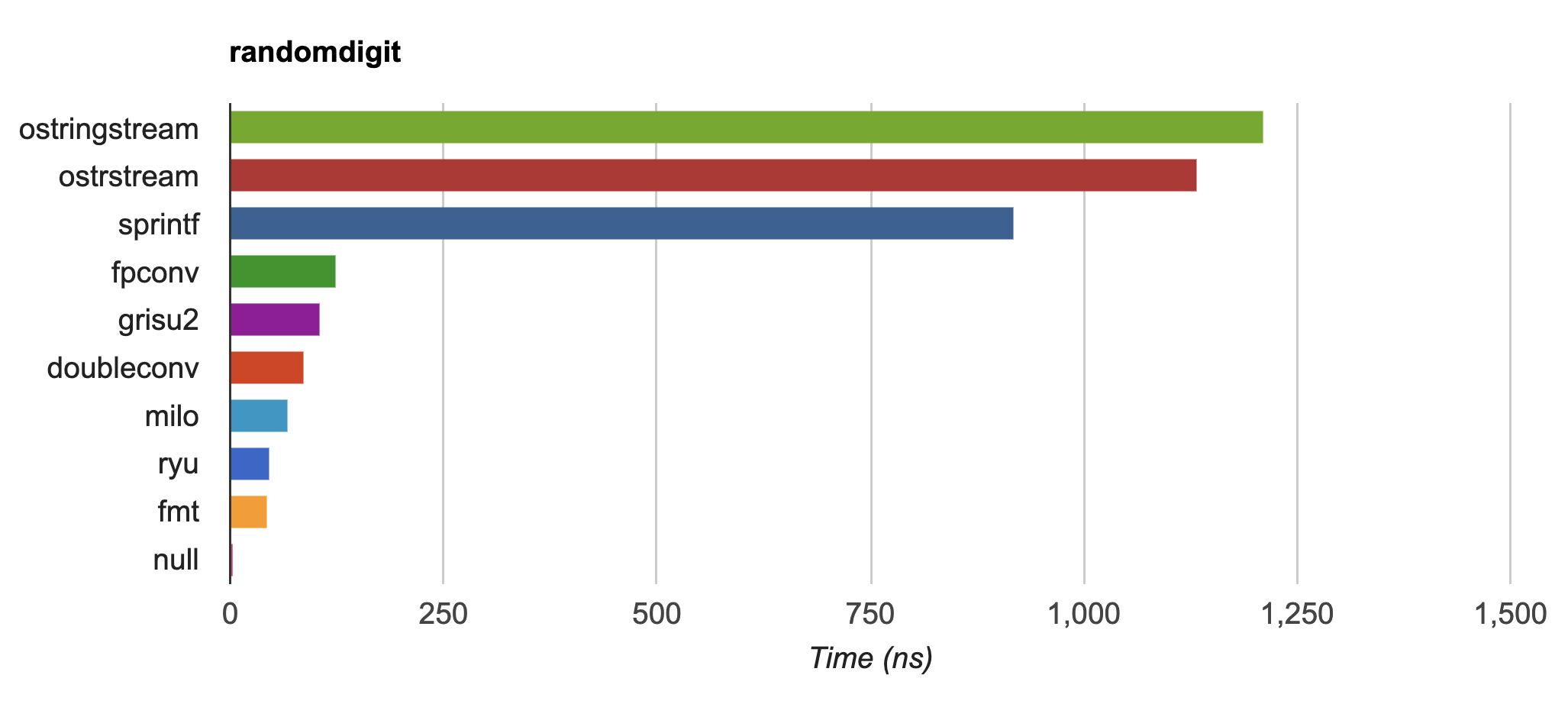](https://fmt.dev/unknown_mac64_clang12.0.html)
|
|
||||||
|
|
||||||
## Compile time and code bloat
|
|
||||||
|
|
||||||
The script [bloat-test.py][test] from [format-benchmark][bench] tests compile
|
|
||||||
time and code bloat for nontrivial projects. It generates 100 translation units
|
|
||||||
and uses `printf()` or its alternative five times in each to simulate a
|
|
||||||
medium-sized project. The resulting executable size and compile time (Apple
|
|
||||||
clang version 15.0.0 (clang-1500.1.0.2.5), macOS Sonoma, best of three) is shown
|
|
||||||
in the following tables.
|
|
||||||
|
|
||||||
[test]: https://github.com/fmtlib/format-benchmark/blob/master/bloat-test.py
|
|
||||||
[bench]: https://github.com/fmtlib/format-benchmark
|
|
||||||
|
|
||||||
**Optimized build (-O3)**
|
|
||||||
|
|
||||||
| Method | Compile Time, s | Executable size, KiB | Stripped size, KiB |
|
|
||||||
|-----------------|-----------------|----------------------|--------------------|
|
|
||||||
| printf | 1.6 | 54 | 50 |
|
|
||||||
| IOStreams | 28.4 | 98 | 84 |
|
|
||||||
| {fmt} `1122268` | 5.0 | 54 | 50 |
|
|
||||||
| tinyformat | 32.6 | 164 | 136 |
|
|
||||||
| Boost Format | 55.0 | 530 | 317 |
|
|
||||||
|
|
||||||
{fmt} is fast to compile and is comparable to `printf` in terms of per-call
|
|
||||||
binary size (within a rounding error on this system).
|
|
||||||
|
|
||||||
**Non-optimized build**
|
|
||||||
|
|
||||||
| Method | Compile Time, s | Executable size, KiB | Stripped size, KiB |
|
|
||||||
|-----------------|-----------------|----------------------|--------------------|
|
|
||||||
| printf | 1.4 | 54 | 50 |
|
|
||||||
| IOStreams | 27.0 | 88 | 68 |
|
|
||||||
| {fmt} `1122268` | 4.7 | 87 | 84 |
|
|
||||||
| tinyformat | 28.1 | 185 | 145 |
|
|
||||||
| Boost Format | 38.9 | 678 | 381 |
|
|
||||||
|
|
||||||
`libc`, `lib(std)c++`, and `libfmt` are all linked as shared libraries
|
|
||||||
to compare formatting function overhead only. Boost Format is a
|
|
||||||
header-only library so it doesn\'t provide any linkage options.
|
|
||||||
|
|
||||||
## Running the tests
|
|
||||||
|
|
||||||
Please refer to [Building the
|
|
||||||
library](https://fmt.dev/latest/get-started/#building-from-source) for
|
|
||||||
instructions on how to build the library and run the unit tests.
|
|
||||||
|
|
||||||
Benchmarks reside in a separate repository,
|
|
||||||
[format-benchmarks](https://github.com/fmtlib/format-benchmark), so to
|
|
||||||
run the benchmarks you first need to clone this repository and generate
|
|
||||||
Makefiles with CMake:
|
|
||||||
|
|
||||||
$ git clone --recursive https://github.com/fmtlib/format-benchmark.git
|
|
||||||
$ cd format-benchmark
|
|
||||||
$ cmake .
|
|
||||||
|
|
||||||
Then you can run the speed test:
|
|
||||||
|
|
||||||
$ make speed-test
|
|
||||||
|
|
||||||
or the bloat test:
|
|
||||||
|
|
||||||
$ make bloat-test
|
|
||||||
|
|
||||||
# Migrating code
|
|
||||||
|
|
||||||
[clang-tidy](https://clang.llvm.org/extra/clang-tidy/) v18 provides the
|
|
||||||
[modernize-use-std-print](https://clang.llvm.org/extra/clang-tidy/checks/modernize/use-std-print.html)
|
|
||||||
check that is capable of converting occurrences of `printf` and
|
|
||||||
`fprintf` to `fmt::print` if configured to do so. (By default it
|
|
||||||
converts to `std::print`.)
|
|
||||||
|
|
||||||
# Notable projects using this library
|
|
||||||
|
|
||||||
- [0 A.D.](https://play0ad.com/): a free, open-source, cross-platform
|
|
||||||
real-time strategy game
|
|
||||||
- [AMPL/MP](https://github.com/ampl/mp): an open-source library for
|
|
||||||
mathematical programming
|
|
||||||
- [Apple's FoundationDB](https://github.com/apple/foundationdb): an open-source,
|
|
||||||
distributed, transactional key-value store
|
|
||||||
- [Aseprite](https://github.com/aseprite/aseprite): animated sprite
|
|
||||||
editor & pixel art tool
|
|
||||||
- [AvioBook](https://www.aviobook.aero/en): a comprehensive aircraft
|
|
||||||
operations suite
|
|
||||||
- [Blizzard Battle.net](https://battle.net/): an online gaming
|
|
||||||
platform
|
|
||||||
- [Celestia](https://celestia.space/): real-time 3D visualization of
|
|
||||||
space
|
|
||||||
- [Ceph](https://ceph.com/): a scalable distributed storage system
|
|
||||||
- [ccache](https://ccache.dev/): a compiler cache
|
|
||||||
- [ClickHouse](https://github.com/ClickHouse/ClickHouse): an
|
|
||||||
analytical database management system
|
|
||||||
- [ContextVision](https://www.contextvision.com/): medical imaging software
|
|
||||||
- [Contour](https://github.com/contour-terminal/contour/): a modern
|
|
||||||
terminal emulator
|
|
||||||
- [CUAUV](https://cuauv.org/): Cornell University\'s autonomous
|
|
||||||
underwater vehicle
|
|
||||||
- [Drake](https://drake.mit.edu/): a planning, control, and analysis
|
|
||||||
toolbox for nonlinear dynamical systems (MIT)
|
|
||||||
- [Envoy](https://github.com/envoyproxy/envoy): C++ L7 proxy and
|
|
||||||
communication bus (Lyft)
|
|
||||||
- [FiveM](https://fivem.net/): a modification framework for GTA V
|
|
||||||
- [fmtlog](https://github.com/MengRao/fmtlog): a performant
|
|
||||||
fmtlib-style logging library with latency in nanoseconds
|
|
||||||
- [Folly](https://github.com/facebook/folly): Facebook open-source
|
|
||||||
library
|
|
||||||
- [GemRB](https://gemrb.org/): a portable open-source implementation
|
|
||||||
of Bioware's Infinity Engine
|
|
||||||
- [Grand Mountain
|
|
||||||
Adventure](https://store.steampowered.com/app/1247360/Grand_Mountain_Adventure/):
|
|
||||||
a beautiful open-world ski & snowboarding game
|
|
||||||
- [HarpyWar/pvpgn](https://github.com/pvpgn/pvpgn-server): Player vs
|
|
||||||
Player Gaming Network with tweaks
|
|
||||||
- [KBEngine](https://github.com/kbengine/kbengine): an open-source
|
|
||||||
MMOG server engine
|
|
||||||
- [Keypirinha](https://keypirinha.com/): a semantic launcher for
|
|
||||||
Windows
|
|
||||||
- [Kodi](https://kodi.tv/) (formerly xbmc): home theater software
|
|
||||||
- [Knuth](https://kth.cash/): high-performance Bitcoin full-node
|
|
||||||
- [libunicode](https://github.com/contour-terminal/libunicode/): a
|
|
||||||
modern C++17 Unicode library
|
|
||||||
- [MariaDB](https://mariadb.org/): relational database management
|
|
||||||
system
|
|
||||||
- [Microsoft Verona](https://github.com/microsoft/verona): research
|
|
||||||
programming language for concurrent ownership
|
|
||||||
- [MongoDB](https://mongodb.com/): distributed document database
|
|
||||||
- [MongoDB Smasher](https://github.com/duckie/mongo_smasher): a small
|
|
||||||
tool to generate randomized datasets
|
|
||||||
- [OpenSpace](https://openspaceproject.com/): an open-source
|
|
||||||
astrovisualization framework
|
|
||||||
- [PenUltima Online (POL)](https://www.polserver.com/): an MMO server,
|
|
||||||
compatible with most Ultima Online clients
|
|
||||||
- [PyTorch](https://github.com/pytorch/pytorch): an open-source
|
|
||||||
machine learning library
|
|
||||||
- [quasardb](https://www.quasardb.net/): a distributed,
|
|
||||||
high-performance, associative database
|
|
||||||
- [Quill](https://github.com/odygrd/quill): asynchronous low-latency
|
|
||||||
logging library
|
|
||||||
- [QKW](https://github.com/ravijanjam/qkw): generalizing aliasing to
|
|
||||||
simplify navigation, and execute complex multi-line terminal
|
|
||||||
command sequences
|
|
||||||
- [redis-cerberus](https://github.com/HunanTV/redis-cerberus): a Redis
|
|
||||||
cluster proxy
|
|
||||||
- [redpanda](https://vectorized.io/redpanda): a 10x faster Kafka®
|
|
||||||
replacement for mission-critical systems written in C++
|
|
||||||
- [rpclib](http://rpclib.net/): a modern C++ msgpack-RPC server and
|
|
||||||
client library
|
|
||||||
- [Salesforce Analytics
|
|
||||||
Cloud](https://www.salesforce.com/analytics-cloud/overview/):
|
|
||||||
business intelligence software
|
|
||||||
- [Scylla](https://www.scylladb.com/): a Cassandra-compatible NoSQL
|
|
||||||
data store that can handle 1 million transactions per second on a
|
|
||||||
single server
|
|
||||||
- [Seastar](http://www.seastar-project.org/): an advanced, open-source
|
|
||||||
C++ framework for high-performance server applications on modern
|
|
||||||
hardware
|
|
||||||
- [spdlog](https://github.com/gabime/spdlog): super fast C++ logging
|
|
||||||
library
|
|
||||||
- [Stellar](https://www.stellar.org/): financial platform
|
|
||||||
- [Touch Surgery](https://www.touchsurgery.com/): surgery simulator
|
|
||||||
- [TrinityCore](https://github.com/TrinityCore/TrinityCore):
|
|
||||||
open-source MMORPG framework
|
|
||||||
- [🐙 userver framework](https://userver.tech/): open-source
|
|
||||||
asynchronous framework with a rich set of abstractions and database
|
|
||||||
drivers
|
|
||||||
- [Windows Terminal](https://github.com/microsoft/terminal): the new
|
|
||||||
Windows terminal
|
|
||||||
|
|
||||||
[More\...](https://github.com/search?q=fmtlib&type=Code)
|
|
||||||
|
|
||||||
If you are aware of other projects using this library, please let me
|
|
||||||
know by [email](mailto:victor.zverovich@gmail.com) or by submitting an
|
|
||||||
[issue](https://github.com/fmtlib/fmt/issues).
|
|
||||||
|
|
||||||
# Motivation
|
|
||||||
|
|
||||||
So why yet another formatting library?
|
|
||||||
|
|
||||||
There are plenty of methods for doing this task, from standard ones like
|
|
||||||
the printf family of function and iostreams to Boost Format and
|
|
||||||
FastFormat libraries. The reason for creating a new library is that
|
|
||||||
every existing solution that I found either had serious issues or
|
|
||||||
didn\'t provide all the features I needed.
|
|
||||||
|
|
||||||
## printf
|
|
||||||
|
|
||||||
The good thing about `printf` is that it is pretty fast and readily
|
|
||||||
available being a part of the C standard library. The main drawback is
|
|
||||||
that it doesn\'t support user-defined types. `printf` also has safety
|
|
||||||
issues although they are somewhat mitigated with [\_\_attribute\_\_
|
|
||||||
((format (printf,
|
|
||||||
\...))](https://gcc.gnu.org/onlinedocs/gcc/Common-Attributes.html) in
|
|
||||||
GCC. There is a POSIX extension that adds positional arguments required
|
|
||||||
for
|
|
||||||
[i18n](https://en.wikipedia.org/wiki/Internationalization_and_localization)
|
|
||||||
to `printf` but it is not a part of C99 and may not be available on some
|
|
||||||
platforms.
|
|
||||||
|
|
||||||
## iostreams
|
|
||||||
|
|
||||||
The main issue with iostreams is best illustrated with an example:
|
|
||||||
|
|
||||||
``` c++
|
|
||||||
std::cout << std::setprecision(2) << std::fixed << 1.23456 << "\n";
|
|
||||||
```
|
|
||||||
|
|
||||||
which is a lot of typing compared to printf:
|
|
||||||
|
|
||||||
``` c++
|
|
||||||
printf("%.2f\n", 1.23456);
|
|
||||||
```
|
|
||||||
|
|
||||||
Matthew Wilson, the author of FastFormat, called this \"chevron hell\".
|
|
||||||
iostreams don\'t support positional arguments by design.
|
|
||||||
|
|
||||||
The good part is that iostreams support user-defined types and are safe
|
|
||||||
although error handling is awkward.
|
|
||||||
|
|
||||||
## Boost Format
|
|
||||||
|
|
||||||
This is a very powerful library that supports both `printf`-like format
|
|
||||||
strings and positional arguments. Its main drawback is performance.
|
|
||||||
According to various benchmarks, it is much slower than other methods
|
|
||||||
considered here. Boost Format also has excessive build times and severe
|
|
||||||
code bloat issues (see [Benchmarks](#benchmarks)).
|
|
||||||
|
|
||||||
## FastFormat
|
|
||||||
|
|
||||||
This is an interesting library that is fast, safe and has positional
|
|
||||||
arguments. However, it has significant limitations, citing its author:
|
|
||||||
|
|
||||||
> Three features that have no hope of being accommodated within the
|
|
||||||
> current design are:
|
|
||||||
>
|
|
||||||
> - Leading zeros (or any other non-space padding)
|
|
||||||
> - Octal/hexadecimal encoding
|
|
||||||
> - Runtime width/alignment specification
|
|
||||||
|
|
||||||
It is also quite big and has a heavy dependency, on STLSoft, which might be
|
|
||||||
too restrictive for use in some projects.
|
|
||||||
|
|
||||||
## Boost Spirit.Karma
|
|
||||||
|
|
||||||
This is not a formatting library but I decided to include it here for
|
|
||||||
completeness. As iostreams, it suffers from the problem of mixing
|
|
||||||
verbatim text with arguments. The library is pretty fast, but slower on
|
|
||||||
integer formatting than `fmt::format_to` with format string compilation
|
|
||||||
on Karma\'s own benchmark, see [Converting a hundred million integers to
|
|
||||||
strings per
|
|
||||||
second](http://www.zverovich.net/2020/06/13/fast-int-to-string-revisited.html).
|
|
||||||
|
|
||||||
# License
|
|
||||||
|
|
||||||
{fmt} is distributed under the MIT
|
|
||||||
[license](https://github.com/fmtlib/fmt/blob/master/LICENSE).
|
|
||||||
|
|
||||||
# Documentation License
|
|
||||||
|
|
||||||
The [Format String Syntax](https://fmt.dev/latest/syntax/) section
|
|
||||||
in the documentation is based on the one from Python [string module
|
|
||||||
documentation](https://docs.python.org/3/library/string.html#module-string).
|
|
||||||
For this reason, the documentation is distributed under the Python
|
|
||||||
Software Foundation license available in
|
|
||||||
[doc/python-license.txt](https://raw.github.com/fmtlib/fmt/master/doc/python-license.txt).
|
|
||||||
It only applies if you distribute the documentation of {fmt}.
|
|
||||||
|
|
||||||
# Maintainers
|
|
||||||
|
|
||||||
The {fmt} library is maintained by Victor Zverovich
|
|
||||||
([vitaut](https://github.com/vitaut)) with contributions from many other
|
|
||||||
people. See
|
|
||||||
[Contributors](https://github.com/fmtlib/fmt/graphs/contributors) and
|
|
||||||
[Releases](https://github.com/fmtlib/fmt/releases) for some of the
|
|
||||||
names. Let us know if your contribution is not listed or mentioned
|
|
||||||
incorrectly and we\'ll make it right.
|
|
||||||
|
|
||||||
# Security Policy
|
|
||||||
|
|
||||||
To report a security issue, please disclose it at [security
|
|
||||||
advisory](https://github.com/fmtlib/fmt/security/advisories/new).
|
|
||||||
|
|
||||||
This project is maintained by a team of volunteers on a
|
|
||||||
reasonable-effort basis. As such, please give us at least *90* days to
|
|
||||||
work on a fix before public exposure.
|
|
||||||
@ -6,9 +6,13 @@ Usage:
|
|||||||
check-commits <start> <source>
|
check-commits <start> <source>
|
||||||
"""
|
"""
|
||||||
|
|
||||||
import docopt, os, sys, tempfile
|
import os
|
||||||
|
import sys
|
||||||
|
import tempfile
|
||||||
from subprocess import check_call, check_output, run
|
from subprocess import check_call, check_output, run
|
||||||
|
|
||||||
|
import docopt
|
||||||
|
|
||||||
args = docopt.docopt(__doc__)
|
args = docopt.docopt(__doc__)
|
||||||
start = args.get('<start>')
|
start = args.get('<start>')
|
||||||
source = args.get('<source>')
|
source = args.get('<source>')
|
||||||
|
|||||||
@ -1,32 +1,30 @@
|
|||||||
"""Pythonic command-line interface parser that will make you smile.
|
"""Pythonic command-line interface parser that will make you smile.
|
||||||
|
|
||||||
* http://docopt.org
|
* http://docopt.org
|
||||||
* Repository and issue-tracker: https://github.com/docopt/docopt
|
* Repository and issue-tracker: https://github.com/docopt/docopt
|
||||||
* Licensed under terms of MIT license (see LICENSE-MIT)
|
* Licensed under terms of MIT license (see LICENSE-MIT)
|
||||||
* Copyright (c) 2013 Vladimir Keleshev, vladimir@keleshev.com
|
* Copyright (c) 2013 Vladimir Keleshev, vladimir@keleshev.com
|
||||||
|
|
||||||
"""
|
"""
|
||||||
import sys
|
|
||||||
import re
|
import re
|
||||||
|
import sys
|
||||||
|
|
||||||
|
__all__ = ["docopt"]
|
||||||
__all__ = ['docopt']
|
__version__ = "0.6.1"
|
||||||
__version__ = '0.6.1'
|
|
||||||
|
|
||||||
|
|
||||||
class DocoptLanguageError(Exception):
|
class DocoptLanguageError(Exception):
|
||||||
|
|
||||||
"""Error in construction of usage-message by developer."""
|
"""Error in construction of usage-message by developer."""
|
||||||
|
|
||||||
|
|
||||||
class DocoptExit(SystemExit):
|
class DocoptExit(SystemExit):
|
||||||
|
|
||||||
"""Exit in case user invoked program with incorrect arguments."""
|
"""Exit in case user invoked program with incorrect arguments."""
|
||||||
|
|
||||||
usage = ''
|
usage = ""
|
||||||
|
|
||||||
def __init__(self, message=''):
|
def __init__(self, message=""):
|
||||||
SystemExit.__init__(self, (message + '\n' + self.usage).strip())
|
SystemExit.__init__(self, (message + "\n" + self.usage).strip())
|
||||||
|
|
||||||
|
|
||||||
class Pattern(object):
|
class Pattern(object):
|
||||||
@ -44,11 +42,11 @@ class Pattern(object):
|
|||||||
|
|
||||||
def fix_identities(self, uniq=None):
|
def fix_identities(self, uniq=None):
|
||||||
"""Make pattern-tree tips point to same object if they are equal."""
|
"""Make pattern-tree tips point to same object if they are equal."""
|
||||||
if not hasattr(self, 'children'):
|
if not hasattr(self, "children"):
|
||||||
return self
|
return self
|
||||||
uniq = list(set(self.flat())) if uniq is None else uniq
|
uniq = list(set(self.flat())) if uniq is None else uniq
|
||||||
for i, child in enumerate(self.children):
|
for i, child in enumerate(self.children):
|
||||||
if not hasattr(child, 'children'):
|
if not hasattr(child, "children"):
|
||||||
assert child in uniq
|
assert child in uniq
|
||||||
self.children[i] = uniq[uniq.index(child)]
|
self.children[i] = uniq[uniq.index(child)]
|
||||||
else:
|
else:
|
||||||
@ -97,14 +95,13 @@ def transform(pattern):
|
|||||||
|
|
||||||
|
|
||||||
class LeafPattern(Pattern):
|
class LeafPattern(Pattern):
|
||||||
|
|
||||||
"""Leaf/terminal node of a pattern tree."""
|
"""Leaf/terminal node of a pattern tree."""
|
||||||
|
|
||||||
def __init__(self, name, value=None):
|
def __init__(self, name, value=None):
|
||||||
self.name, self.value = name, value
|
self.name, self.value = name, value
|
||||||
|
|
||||||
def __repr__(self):
|
def __repr__(self):
|
||||||
return '%s(%r, %r)' % (self.__class__.__name__, self.name, self.value)
|
return "%s(%r, %r)" % (self.__class__.__name__, self.name, self.value)
|
||||||
|
|
||||||
def flat(self, *types):
|
def flat(self, *types):
|
||||||
return [self] if not types or type(self) in types else []
|
return [self] if not types or type(self) in types else []
|
||||||
@ -114,14 +111,13 @@ class LeafPattern(Pattern):
|
|||||||
pos, match = self.single_match(left)
|
pos, match = self.single_match(left)
|
||||||
if match is None:
|
if match is None:
|
||||||
return False, left, collected
|
return False, left, collected
|
||||||
left_ = left[:pos] + left[pos + 1:]
|
left_ = left[:pos] + left[pos + 1 :]
|
||||||
same_name = [a for a in collected if a.name == self.name]
|
same_name = [a for a in collected if a.name == self.name]
|
||||||
if type(self.value) in (int, list):
|
if type(self.value) in (int, list):
|
||||||
if type(self.value) is int:
|
if type(self.value) is int:
|
||||||
increment = 1
|
increment = 1
|
||||||
else:
|
else:
|
||||||
increment = ([match.value] if type(match.value) is str
|
increment = [match.value] if type(match.value) is str else match.value
|
||||||
else match.value)
|
|
||||||
if not same_name:
|
if not same_name:
|
||||||
match.value = increment
|
match.value = increment
|
||||||
return True, left_, collected + [match]
|
return True, left_, collected + [match]
|
||||||
@ -131,15 +127,16 @@ class LeafPattern(Pattern):
|
|||||||
|
|
||||||
|
|
||||||
class BranchPattern(Pattern):
|
class BranchPattern(Pattern):
|
||||||
|
|
||||||
"""Branch/inner node of a pattern tree."""
|
"""Branch/inner node of a pattern tree."""
|
||||||
|
|
||||||
def __init__(self, *children):
|
def __init__(self, *children):
|
||||||
self.children = list(children)
|
self.children = list(children)
|
||||||
|
|
||||||
def __repr__(self):
|
def __repr__(self):
|
||||||
return '%s(%s)' % (self.__class__.__name__,
|
return "%s(%s)" % (
|
||||||
', '.join(repr(a) for a in self.children))
|
self.__class__.__name__,
|
||||||
|
", ".join(repr(a) for a in self.children),
|
||||||
|
)
|
||||||
|
|
||||||
def flat(self, *types):
|
def flat(self, *types):
|
||||||
if type(self) in types:
|
if type(self) in types:
|
||||||
@ -157,8 +154,8 @@ class Argument(LeafPattern):
|
|||||||
|
|
||||||
@classmethod
|
@classmethod
|
||||||
def parse(class_, source):
|
def parse(class_, source):
|
||||||
name = re.findall('(<\S*?>)', source)[0]
|
name = re.findall("(<\S*?>)", source)[0]
|
||||||
value = re.findall('\[default: (.*)\]', source, flags=re.I)
|
value = re.findall("\[default: (.*)\]", source, flags=re.I)
|
||||||
return class_(name, value[0] if value else None)
|
return class_(name, value[0] if value else None)
|
||||||
|
|
||||||
|
|
||||||
@ -187,17 +184,17 @@ class Option(LeafPattern):
|
|||||||
@classmethod
|
@classmethod
|
||||||
def parse(class_, option_description):
|
def parse(class_, option_description):
|
||||||
short, long, argcount, value = None, None, 0, False
|
short, long, argcount, value = None, None, 0, False
|
||||||
options, _, description = option_description.strip().partition(' ')
|
options, _, description = option_description.strip().partition(" ")
|
||||||
options = options.replace(',', ' ').replace('=', ' ')
|
options = options.replace(",", " ").replace("=", " ")
|
||||||
for s in options.split():
|
for s in options.split():
|
||||||
if s.startswith('--'):
|
if s.startswith("--"):
|
||||||
long = s
|
long = s
|
||||||
elif s.startswith('-'):
|
elif s.startswith("-"):
|
||||||
short = s
|
short = s
|
||||||
else:
|
else:
|
||||||
argcount = 1
|
argcount = 1
|
||||||
if argcount:
|
if argcount:
|
||||||
matched = re.findall('\[default: (.*)\]', description, flags=re.I)
|
matched = re.findall("\[default: (.*)\]", description, flags=re.I)
|
||||||
value = matched[0] if matched else None
|
value = matched[0] if matched else None
|
||||||
return class_(short, long, argcount, value)
|
return class_(short, long, argcount, value)
|
||||||
|
|
||||||
@ -212,8 +209,12 @@ class Option(LeafPattern):
|
|||||||
return self.long or self.short
|
return self.long or self.short
|
||||||
|
|
||||||
def __repr__(self):
|
def __repr__(self):
|
||||||
return 'Option(%r, %r, %r, %r)' % (self.short, self.long,
|
return "Option(%r, %r, %r, %r)" % (
|
||||||
self.argcount, self.value)
|
self.short,
|
||||||
|
self.long,
|
||||||
|
self.argcount,
|
||||||
|
self.value,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
class Required(BranchPattern):
|
class Required(BranchPattern):
|
||||||
@ -239,7 +240,6 @@ class Optional(BranchPattern):
|
|||||||
|
|
||||||
|
|
||||||
class OptionsShortcut(Optional):
|
class OptionsShortcut(Optional):
|
||||||
|
|
||||||
"""Marker/placeholder for [options] shortcut."""
|
"""Marker/placeholder for [options] shortcut."""
|
||||||
|
|
||||||
|
|
||||||
@ -282,13 +282,13 @@ class Either(BranchPattern):
|
|||||||
class Tokens(list):
|
class Tokens(list):
|
||||||
|
|
||||||
def __init__(self, source, error=DocoptExit):
|
def __init__(self, source, error=DocoptExit):
|
||||||
self += source.split() if hasattr(source, 'split') else source
|
self += source.split() if hasattr(source, "split") else source
|
||||||
self.error = error
|
self.error = error
|
||||||
|
|
||||||
@staticmethod
|
@staticmethod
|
||||||
def from_pattern(source):
|
def from_pattern(source):
|
||||||
source = re.sub(r'([\[\]\(\)\|]|\.\.\.)', r' \1 ', source)
|
source = re.sub(r"([\[\]\(\)\|]|\.\.\.)", r" \1 ", source)
|
||||||
source = [s for s in re.split('\s+|(\S*<.*?>)', source) if s]
|
source = [s for s in re.split("\s+|(\S*<.*?>)", source) if s]
|
||||||
return Tokens(source, error=DocoptLanguageError)
|
return Tokens(source, error=DocoptLanguageError)
|
||||||
|
|
||||||
def move(self):
|
def move(self):
|
||||||
@ -300,31 +300,34 @@ class Tokens(list):
|
|||||||
|
|
||||||
def parse_long(tokens, options):
|
def parse_long(tokens, options):
|
||||||
"""long ::= '--' chars [ ( ' ' | '=' ) chars ] ;"""
|
"""long ::= '--' chars [ ( ' ' | '=' ) chars ] ;"""
|
||||||
long, eq, value = tokens.move().partition('=')
|
long, eq, value = tokens.move().partition("=")
|
||||||
assert long.startswith('--')
|
assert long.startswith("--")
|
||||||
value = None if eq == value == '' else value
|
value = None if eq == value == "" else value
|
||||||
similar = [o for o in options if o.long == long]
|
similar = [o for o in options if o.long == long]
|
||||||
if tokens.error is DocoptExit and similar == []: # if no exact match
|
if tokens.error is DocoptExit and similar == []: # if no exact match
|
||||||
similar = [o for o in options if o.long and o.long.startswith(long)]
|
similar = [o for o in options if o.long and o.long.startswith(long)]
|
||||||
if len(similar) > 1: # might be simply specified ambiguously 2+ times?
|
if len(similar) > 1: # might be simply specified ambiguously 2+ times?
|
||||||
raise tokens.error('%s is not a unique prefix: %s?' %
|
raise tokens.error(
|
||||||
(long, ', '.join(o.long for o in similar)))
|
"%s is not a unique prefix: %s?"
|
||||||
|
% (long, ", ".join(o.long for o in similar))
|
||||||
|
)
|
||||||
elif len(similar) < 1:
|
elif len(similar) < 1:
|
||||||
argcount = 1 if eq == '=' else 0
|
argcount = 1 if eq == "=" else 0
|
||||||
o = Option(None, long, argcount)
|
o = Option(None, long, argcount)
|
||||||
options.append(o)
|
options.append(o)
|
||||||
if tokens.error is DocoptExit:
|
if tokens.error is DocoptExit:
|
||||||
o = Option(None, long, argcount, value if argcount else True)
|
o = Option(None, long, argcount, value if argcount else True)
|
||||||
else:
|
else:
|
||||||
o = Option(similar[0].short, similar[0].long,
|
o = Option(
|
||||||
similar[0].argcount, similar[0].value)
|
similar[0].short, similar[0].long, similar[0].argcount, similar[0].value
|
||||||
|
)
|
||||||
if o.argcount == 0:
|
if o.argcount == 0:
|
||||||
if value is not None:
|
if value is not None:
|
||||||
raise tokens.error('%s must not have an argument' % o.long)
|
raise tokens.error("%s must not have an argument" % o.long)
|
||||||
else:
|
else:
|
||||||
if value is None:
|
if value is None:
|
||||||
if tokens.current() in [None, '--']:
|
if tokens.current() in [None, "--"]:
|
||||||
raise tokens.error('%s requires argument' % o.long)
|
raise tokens.error("%s requires argument" % o.long)
|
||||||
value = tokens.move()
|
value = tokens.move()
|
||||||
if tokens.error is DocoptExit:
|
if tokens.error is DocoptExit:
|
||||||
o.value = value if value is not None else True
|
o.value = value if value is not None else True
|
||||||
@ -334,32 +337,32 @@ def parse_long(tokens, options):
|
|||||||
def parse_shorts(tokens, options):
|
def parse_shorts(tokens, options):
|
||||||
"""shorts ::= '-' ( chars )* [ [ ' ' ] chars ] ;"""
|
"""shorts ::= '-' ( chars )* [ [ ' ' ] chars ] ;"""
|
||||||
token = tokens.move()
|
token = tokens.move()
|
||||||
assert token.startswith('-') and not token.startswith('--')
|
assert token.startswith("-") and not token.startswith("--")
|
||||||
left = token.lstrip('-')
|
left = token.lstrip("-")
|
||||||
parsed = []
|
parsed = []
|
||||||
while left != '':
|
while left != "":
|
||||||
short, left = '-' + left[0], left[1:]
|
short, left = "-" + left[0], left[1:]
|
||||||
similar = [o for o in options if o.short == short]
|
similar = [o for o in options if o.short == short]
|
||||||
if len(similar) > 1:
|
if len(similar) > 1:
|
||||||
raise tokens.error('%s is specified ambiguously %d times' %
|
raise tokens.error(
|
||||||
(short, len(similar)))
|
"%s is specified ambiguously %d times" % (short, len(similar))
|
||||||
|
)
|
||||||
elif len(similar) < 1:
|
elif len(similar) < 1:
|
||||||
o = Option(short, None, 0)
|
o = Option(short, None, 0)
|
||||||
options.append(o)
|
options.append(o)
|
||||||
if tokens.error is DocoptExit:
|
if tokens.error is DocoptExit:
|
||||||
o = Option(short, None, 0, True)
|
o = Option(short, None, 0, True)
|
||||||
else: # why copying is necessary here?
|
else: # why copying is necessary here?
|
||||||
o = Option(short, similar[0].long,
|
o = Option(short, similar[0].long, similar[0].argcount, similar[0].value)
|
||||||
similar[0].argcount, similar[0].value)
|
|
||||||
value = None
|
value = None
|
||||||
if o.argcount != 0:
|
if o.argcount != 0:
|
||||||
if left == '':
|
if left == "":
|
||||||
if tokens.current() in [None, '--']:
|
if tokens.current() in [None, "--"]:
|
||||||
raise tokens.error('%s requires argument' % short)
|
raise tokens.error("%s requires argument" % short)
|
||||||
value = tokens.move()
|
value = tokens.move()
|
||||||
else:
|
else:
|
||||||
value = left
|
value = left
|
||||||
left = ''
|
left = ""
|
||||||
if tokens.error is DocoptExit:
|
if tokens.error is DocoptExit:
|
||||||
o.value = value if value is not None else True
|
o.value = value if value is not None else True
|
||||||
parsed.append(o)
|
parsed.append(o)
|
||||||
@ -370,17 +373,17 @@ def parse_pattern(source, options):
|
|||||||
tokens = Tokens.from_pattern(source)
|
tokens = Tokens.from_pattern(source)
|
||||||
result = parse_expr(tokens, options)
|
result = parse_expr(tokens, options)
|
||||||
if tokens.current() is not None:
|
if tokens.current() is not None:
|
||||||
raise tokens.error('unexpected ending: %r' % ' '.join(tokens))
|
raise tokens.error("unexpected ending: %r" % " ".join(tokens))
|
||||||
return Required(*result)
|
return Required(*result)
|
||||||
|
|
||||||
|
|
||||||
def parse_expr(tokens, options):
|
def parse_expr(tokens, options):
|
||||||
"""expr ::= seq ( '|' seq )* ;"""
|
"""expr ::= seq ( '|' seq )* ;"""
|
||||||
seq = parse_seq(tokens, options)
|
seq = parse_seq(tokens, options)
|
||||||
if tokens.current() != '|':
|
if tokens.current() != "|":
|
||||||
return seq
|
return seq
|
||||||
result = [Required(*seq)] if len(seq) > 1 else seq
|
result = [Required(*seq)] if len(seq) > 1 else seq
|
||||||
while tokens.current() == '|':
|
while tokens.current() == "|":
|
||||||
tokens.move()
|
tokens.move()
|
||||||
seq = parse_seq(tokens, options)
|
seq = parse_seq(tokens, options)
|
||||||
result += [Required(*seq)] if len(seq) > 1 else seq
|
result += [Required(*seq)] if len(seq) > 1 else seq
|
||||||
@ -390,9 +393,9 @@ def parse_expr(tokens, options):
|
|||||||
def parse_seq(tokens, options):
|
def parse_seq(tokens, options):
|
||||||
"""seq ::= ( atom [ '...' ] )* ;"""
|
"""seq ::= ( atom [ '...' ] )* ;"""
|
||||||
result = []
|
result = []
|
||||||
while tokens.current() not in [None, ']', ')', '|']:
|
while tokens.current() not in [None, "]", ")", "|"]:
|
||||||
atom = parse_atom(tokens, options)
|
atom = parse_atom(tokens, options)
|
||||||
if tokens.current() == '...':
|
if tokens.current() == "...":
|
||||||
atom = [OneOrMore(*atom)]
|
atom = [OneOrMore(*atom)]
|
||||||
tokens.move()
|
tokens.move()
|
||||||
result += atom
|
result += atom
|
||||||
@ -401,25 +404,25 @@ def parse_seq(tokens, options):
|
|||||||
|
|
||||||
def parse_atom(tokens, options):
|
def parse_atom(tokens, options):
|
||||||
"""atom ::= '(' expr ')' | '[' expr ']' | 'options'
|
"""atom ::= '(' expr ')' | '[' expr ']' | 'options'
|
||||||
| long | shorts | argument | command ;
|
| long | shorts | argument | command ;
|
||||||
"""
|
"""
|
||||||
token = tokens.current()
|
token = tokens.current()
|
||||||
result = []
|
result = []
|
||||||
if token in '([':
|
if token in "([":
|
||||||
tokens.move()
|
tokens.move()
|
||||||
matching, pattern = {'(': [')', Required], '[': [']', Optional]}[token]
|
matching, pattern = {"(": [")", Required], "[": ["]", Optional]}[token]
|
||||||
result = pattern(*parse_expr(tokens, options))
|
result = pattern(*parse_expr(tokens, options))
|
||||||
if tokens.move() != matching:
|
if tokens.move() != matching:
|
||||||
raise tokens.error("unmatched '%s'" % token)
|
raise tokens.error("unmatched '%s'" % token)
|
||||||
return [result]
|
return [result]
|
||||||
elif token == 'options':
|
elif token == "options":
|
||||||
tokens.move()
|
tokens.move()
|
||||||
return [OptionsShortcut()]
|
return [OptionsShortcut()]
|
||||||
elif token.startswith('--') and token != '--':
|
elif token.startswith("--") and token != "--":
|
||||||
return parse_long(tokens, options)
|
return parse_long(tokens, options)
|
||||||
elif token.startswith('-') and token not in ('-', '--'):
|
elif token.startswith("-") and token not in ("-", "--"):
|
||||||
return parse_shorts(tokens, options)
|
return parse_shorts(tokens, options)
|
||||||
elif token.startswith('<') and token.endswith('>') or token.isupper():
|
elif token.startswith("<") and token.endswith(">") or token.isupper():
|
||||||
return [Argument(tokens.move())]
|
return [Argument(tokens.move())]
|
||||||
else:
|
else:
|
||||||
return [Command(tokens.move())]
|
return [Command(tokens.move())]
|
||||||
@ -436,11 +439,11 @@ def parse_argv(tokens, options, options_first=False):
|
|||||||
"""
|
"""
|
||||||
parsed = []
|
parsed = []
|
||||||
while tokens.current() is not None:
|
while tokens.current() is not None:
|
||||||
if tokens.current() == '--':
|
if tokens.current() == "--":
|
||||||
return parsed + [Argument(None, v) for v in tokens]
|
return parsed + [Argument(None, v) for v in tokens]
|
||||||
elif tokens.current().startswith('--'):
|
elif tokens.current().startswith("--"):
|
||||||
parsed += parse_long(tokens, options)
|
parsed += parse_long(tokens, options)
|
||||||
elif tokens.current().startswith('-') and tokens.current() != '-':
|
elif tokens.current().startswith("-") and tokens.current() != "-":
|
||||||
parsed += parse_shorts(tokens, options)
|
parsed += parse_shorts(tokens, options)
|
||||||
elif options_first:
|
elif options_first:
|
||||||
return parsed + [Argument(None, v) for v in tokens]
|
return parsed + [Argument(None, v) for v in tokens]
|
||||||
@ -451,40 +454,42 @@ def parse_argv(tokens, options, options_first=False):
|
|||||||
|
|
||||||
def parse_defaults(doc):
|
def parse_defaults(doc):
|
||||||
defaults = []
|
defaults = []
|
||||||
for s in parse_section('options:', doc):
|
for s in parse_section("options:", doc):
|
||||||
# FIXME corner case "bla: options: --foo"
|
# FIXME corner case "bla: options: --foo"
|
||||||
_, _, s = s.partition(':') # get rid of "options:"
|
_, _, s = s.partition(":") # get rid of "options:"
|
||||||
split = re.split('\n[ \t]*(-\S+?)', '\n' + s)[1:]
|
split = re.split("\n[ \t]*(-\S+?)", "\n" + s)[1:]
|
||||||
split = [s1 + s2 for s1, s2 in zip(split[::2], split[1::2])]
|
split = [s1 + s2 for s1, s2 in zip(split[::2], split[1::2])]
|
||||||
options = [Option.parse(s) for s in split if s.startswith('-')]
|
options = [Option.parse(s) for s in split if s.startswith("-")]
|
||||||
defaults += options
|
defaults += options
|
||||||
return defaults
|
return defaults
|
||||||
|
|
||||||
|
|
||||||
def parse_section(name, source):
|
def parse_section(name, source):
|
||||||
pattern = re.compile('^([^\n]*' + name + '[^\n]*\n?(?:[ \t].*?(?:\n|$))*)',
|
pattern = re.compile(
|
||||||
re.IGNORECASE | re.MULTILINE)
|
"^([^\n]*" + name + "[^\n]*\n?(?:[ \t].*?(?:\n|$))*)",
|
||||||
|
re.IGNORECASE | re.MULTILINE,
|
||||||
|
)
|
||||||
return [s.strip() for s in pattern.findall(source)]
|
return [s.strip() for s in pattern.findall(source)]
|
||||||
|
|
||||||
|
|
||||||
def formal_usage(section):
|
def formal_usage(section):
|
||||||
_, _, section = section.partition(':') # drop "usage:"
|
_, _, section = section.partition(":") # drop "usage:"
|
||||||
pu = section.split()
|
pu = section.split()
|
||||||
return '( ' + ' '.join(') | (' if s == pu[0] else s for s in pu[1:]) + ' )'
|
return "( " + " ".join(") | (" if s == pu[0] else s for s in pu[1:]) + " )"
|
||||||
|
|
||||||
|
|
||||||
def extras(help, version, options, doc):
|
def extras(help, version, options, doc):
|
||||||
if help and any((o.name in ('-h', '--help')) and o.value for o in options):
|
if help and any((o.name in ("-h", "--help")) and o.value for o in options):
|
||||||
print(doc.strip("\n"))
|
print(doc.strip("\n"))
|
||||||
sys.exit()
|
sys.exit()
|
||||||
if version and any(o.name == '--version' and o.value for o in options):
|
if version and any(o.name == "--version" and o.value for o in options):
|
||||||
print(version)
|
print(version)
|
||||||
sys.exit()
|
sys.exit()
|
||||||
|
|
||||||
|
|
||||||
class Dict(dict):
|
class Dict(dict):
|
||||||
def __repr__(self):
|
def __repr__(self):
|
||||||
return '{%s}' % ',\n '.join('%r: %r' % i for i in sorted(self.items()))
|
return "{%s}" % ",\n ".join("%r: %r" % i for i in sorted(self.items()))
|
||||||
|
|
||||||
|
|
||||||
def docopt(doc, argv=None, help=True, version=None, options_first=False):
|
def docopt(doc, argv=None, help=True, version=None, options_first=False):
|
||||||
@ -552,7 +557,7 @@ def docopt(doc, argv=None, help=True, version=None, options_first=False):
|
|||||||
"""
|
"""
|
||||||
argv = sys.argv[1:] if argv is None else argv
|
argv = sys.argv[1:] if argv is None else argv
|
||||||
|
|
||||||
usage_sections = parse_section('usage:', doc)
|
usage_sections = parse_section("usage:", doc)
|
||||||
if len(usage_sections) == 0:
|
if len(usage_sections) == 0:
|
||||||
raise DocoptLanguageError('"usage:" (case-insensitive) not found.')
|
raise DocoptLanguageError('"usage:" (case-insensitive) not found.')
|
||||||
if len(usage_sections) > 1:
|
if len(usage_sections) > 1:
|
||||||
@ -562,7 +567,7 @@ def docopt(doc, argv=None, help=True, version=None, options_first=False):
|
|||||||
options = parse_defaults(doc)
|
options = parse_defaults(doc)
|
||||||
pattern = parse_pattern(formal_usage(DocoptExit.usage), options)
|
pattern = parse_pattern(formal_usage(DocoptExit.usage), options)
|
||||||
# [default] syntax for argument is disabled
|
# [default] syntax for argument is disabled
|
||||||
#for a in pattern.flat(Argument):
|
# for a in pattern.flat(Argument):
|
||||||
# same_name = [d for d in arguments if d.name == a.name]
|
# same_name = [d for d in arguments if d.name == a.name]
|
||||||
# if same_name:
|
# if same_name:
|
||||||
# a.value = same_name[0].value
|
# a.value = same_name[0].value
|
||||||
@ -571,7 +576,7 @@ def docopt(doc, argv=None, help=True, version=None, options_first=False):
|
|||||||
for options_shortcut in pattern.flat(OptionsShortcut):
|
for options_shortcut in pattern.flat(OptionsShortcut):
|
||||||
doc_options = parse_defaults(doc)
|
doc_options = parse_defaults(doc)
|
||||||
options_shortcut.children = list(set(doc_options) - pattern_options)
|
options_shortcut.children = list(set(doc_options) - pattern_options)
|
||||||
#if any_options:
|
# if any_options:
|
||||||
# options_shortcut.children += [Option(o.short, o.long, o.argcount)
|
# options_shortcut.children += [Option(o.short, o.long, o.argcount)
|
||||||
# for o in argv if type(o) is Option]
|
# for o in argv if type(o) is Option]
|
||||||
extras(help, version, argv, doc)
|
extras(help, version, argv, doc)
|
||||||
|
|||||||
@ -7,7 +7,10 @@
|
|||||||
# This will checkout the website to fmt/build/fmt.dev and deploy documentation
|
# This will checkout the website to fmt/build/fmt.dev and deploy documentation
|
||||||
# <version> there.
|
# <version> there.
|
||||||
|
|
||||||
import errno, os, shutil, sys
|
import errno
|
||||||
|
import os
|
||||||
|
import shutil
|
||||||
|
import sys
|
||||||
from subprocess import call
|
from subprocess import call
|
||||||
|
|
||||||
support_dir = os.path.dirname(os.path.normpath(__file__))
|
support_dir = os.path.dirname(os.path.normpath(__file__))
|
||||||
|
|||||||
@ -8,12 +8,13 @@
|
|||||||
# - UnicodeData.txt
|
# - UnicodeData.txt
|
||||||
|
|
||||||
|
|
||||||
from collections import namedtuple
|
|
||||||
import csv
|
import csv
|
||||||
import os
|
import os
|
||||||
import subprocess
|
import subprocess
|
||||||
|
from collections import namedtuple
|
||||||
|
|
||||||
|
NUM_CODEPOINTS = 0x110000
|
||||||
|
|
||||||
NUM_CODEPOINTS=0x110000
|
|
||||||
|
|
||||||
def to_ranges(iter):
|
def to_ranges(iter):
|
||||||
current = None
|
current = None
|
||||||
@ -27,11 +28,15 @@ def to_ranges(iter):
|
|||||||
if current is not None:
|
if current is not None:
|
||||||
yield tuple(current)
|
yield tuple(current)
|
||||||
|
|
||||||
|
|
||||||
def get_escaped(codepoints):
|
def get_escaped(codepoints):
|
||||||
for c in codepoints:
|
for c in codepoints:
|
||||||
if (c.class_ or "Cn") in "Cc Cf Cs Co Cn Zl Zp Zs".split() and c.value != ord(' '):
|
if (c.class_ or "Cn") in "Cc Cf Cs Co Cn Zl Zp Zs".split() and c.value != ord(
|
||||||
|
" "
|
||||||
|
):
|
||||||
yield c.value
|
yield c.value
|
||||||
|
|
||||||
|
|
||||||
def get_file(f):
|
def get_file(f):
|
||||||
try:
|
try:
|
||||||
return open(os.path.basename(f))
|
return open(os.path.basename(f))
|
||||||
@ -39,7 +44,9 @@ def get_file(f):
|
|||||||
subprocess.run(["curl", "-O", f], check=True)
|
subprocess.run(["curl", "-O", f], check=True)
|
||||||
return open(os.path.basename(f))
|
return open(os.path.basename(f))
|
||||||
|
|
||||||
Codepoint = namedtuple('Codepoint', 'value class_')
|
|
||||||
|
Codepoint = namedtuple("Codepoint", "value class_")
|
||||||
|
|
||||||
|
|
||||||
def get_codepoints(f):
|
def get_codepoints(f):
|
||||||
r = csv.reader(f, delimiter=";")
|
r = csv.reader(f, delimiter=";")
|
||||||
@ -70,13 +77,14 @@ def get_codepoints(f):
|
|||||||
for c in range(prev_codepoint + 1, NUM_CODEPOINTS):
|
for c in range(prev_codepoint + 1, NUM_CODEPOINTS):
|
||||||
yield Codepoint(c, None)
|
yield Codepoint(c, None)
|
||||||
|
|
||||||
|
|
||||||
def compress_singletons(singletons):
|
def compress_singletons(singletons):
|
||||||
uppers = [] # (upper, # items in lowers)
|
uppers = [] # (upper, # items in lowers)
|
||||||
lowers = []
|
lowers = []
|
||||||
|
|
||||||
for i in singletons:
|
for i in singletons:
|
||||||
upper = i >> 8
|
upper = i >> 8
|
||||||
lower = i & 0xff
|
lower = i & 0xFF
|
||||||
if len(uppers) == 0 or uppers[-1][0] != upper:
|
if len(uppers) == 0 or uppers[-1][0] != upper:
|
||||||
uppers.append((upper, 1))
|
uppers.append((upper, 1))
|
||||||
else:
|
else:
|
||||||
@ -86,10 +94,11 @@ def compress_singletons(singletons):
|
|||||||
|
|
||||||
return uppers, lowers
|
return uppers, lowers
|
||||||
|
|
||||||
|
|
||||||
def compress_normal(normal):
|
def compress_normal(normal):
|
||||||
# lengths 0x00..0x7f are encoded as 00, 01, ..., 7e, 7f
|
# lengths 0x00..0x7f are encoded as 00, 01, ..., 7e, 7f
|
||||||
# lengths 0x80..0x7fff are encoded as 80 80, 80 81, ..., ff fe, ff ff
|
# lengths 0x80..0x7fff are encoded as 80 80, 80 81, ..., ff fe, ff ff
|
||||||
compressed = [] # [truelen, (truelenaux), falselen, (falselenaux)]
|
compressed = [] # [truelen, (truelenaux), falselen, (falselenaux)]
|
||||||
|
|
||||||
prev_start = 0
|
prev_start = 0
|
||||||
for start, count in normal:
|
for start, count in normal:
|
||||||
@ -99,21 +108,22 @@ def compress_normal(normal):
|
|||||||
|
|
||||||
assert truelen < 0x8000 and falselen < 0x8000
|
assert truelen < 0x8000 and falselen < 0x8000
|
||||||
entry = []
|
entry = []
|
||||||
if truelen > 0x7f:
|
if truelen > 0x7F:
|
||||||
entry.append(0x80 | (truelen >> 8))
|
entry.append(0x80 | (truelen >> 8))
|
||||||
entry.append(truelen & 0xff)
|
entry.append(truelen & 0xFF)
|
||||||
else:
|
else:
|
||||||
entry.append(truelen & 0x7f)
|
entry.append(truelen & 0x7F)
|
||||||
if falselen > 0x7f:
|
if falselen > 0x7F:
|
||||||
entry.append(0x80 | (falselen >> 8))
|
entry.append(0x80 | (falselen >> 8))
|
||||||
entry.append(falselen & 0xff)
|
entry.append(falselen & 0xFF)
|
||||||
else:
|
else:
|
||||||
entry.append(falselen & 0x7f)
|
entry.append(falselen & 0x7F)
|
||||||
|
|
||||||
compressed.append(entry)
|
compressed.append(entry)
|
||||||
|
|
||||||
return compressed
|
return compressed
|
||||||
|
|
||||||
|
|
||||||
def print_singletons(uppers, lowers, uppersname, lowersname):
|
def print_singletons(uppers, lowers, uppersname, lowersname):
|
||||||
print(" static constexpr singleton {}[] = {{".format(uppersname))
|
print(" static constexpr singleton {}[] = {{".format(uppersname))
|
||||||
for u, c in uppers:
|
for u, c in uppers:
|
||||||
@ -121,21 +131,25 @@ def print_singletons(uppers, lowers, uppersname, lowersname):
|
|||||||
print(" };")
|
print(" };")
|
||||||
print(" static constexpr unsigned char {}[] = {{".format(lowersname))
|
print(" static constexpr unsigned char {}[] = {{".format(lowersname))
|
||||||
for i in range(0, len(lowers), 8):
|
for i in range(0, len(lowers), 8):
|
||||||
print(" {}".format(" ".join("{:#04x},".format(l) for l in lowers[i:i+8])))
|
print(
|
||||||
|
" {}".format(" ".join("{:#04x},".format(l) for l in lowers[i : i + 8]))
|
||||||
|
)
|
||||||
print(" };")
|
print(" };")
|
||||||
|
|
||||||
|
|
||||||
def print_normal(normal, normalname):
|
def print_normal(normal, normalname):
|
||||||
print(" static constexpr unsigned char {}[] = {{".format(normalname))
|
print(" static constexpr unsigned char {}[] = {{".format(normalname))
|
||||||
for v in normal:
|
for v in normal:
|
||||||
print(" {}".format(" ".join("{:#04x},".format(i) for i in v)))
|
print(" {}".format(" ".join("{:#04x},".format(i) for i in v)))
|
||||||
print(" };")
|
print(" };")
|
||||||
|
|
||||||
|
|
||||||
def main():
|
def main():
|
||||||
file = get_file("https://www.unicode.org/Public/UNIDATA/UnicodeData.txt")
|
file = get_file("https://www.unicode.org/Public/UNIDATA/UnicodeData.txt")
|
||||||
|
|
||||||
codepoints = get_codepoints(file)
|
codepoints = get_codepoints(file)
|
||||||
|
|
||||||
CUTOFF=0x10000
|
CUTOFF = 0x10000
|
||||||
singletons0 = []
|
singletons0 = []
|
||||||
singletons1 = []
|
singletons1 = []
|
||||||
normal0 = []
|
normal0 = []
|
||||||
@ -173,10 +187,10 @@ def main():
|
|||||||
print("""\
|
print("""\
|
||||||
FMT_FUNC auto is_printable(uint32_t cp) -> bool {\
|
FMT_FUNC auto is_printable(uint32_t cp) -> bool {\
|
||||||
""")
|
""")
|
||||||
print_singletons(singletons0u, singletons0l, 'singletons0', 'singletons0_lower')
|
print_singletons(singletons0u, singletons0l, "singletons0", "singletons0_lower")
|
||||||
print_singletons(singletons1u, singletons1l, 'singletons1', 'singletons1_lower')
|
print_singletons(singletons1u, singletons1l, "singletons1", "singletons1_lower")
|
||||||
print_normal(normal0, 'normal0')
|
print_normal(normal0, "normal0")
|
||||||
print_normal(normal1, 'normal1')
|
print_normal(normal1, "normal1")
|
||||||
print("""\
|
print("""\
|
||||||
auto lower = static_cast<uint16_t>(cp);
|
auto lower = static_cast<uint16_t>(cp);
|
||||||
if (cp < 0x10000) {
|
if (cp < 0x10000) {
|
||||||
@ -197,5 +211,6 @@ FMT_FUNC auto is_printable(uint32_t cp) -> bool {\
|
|||||||
}}\
|
}}\
|
||||||
""".format(NUM_CODEPOINTS))
|
""".format(NUM_CODEPOINTS))
|
||||||
|
|
||||||
if __name__ == '__main__':
|
|
||||||
|
if __name__ == "__main__":
|
||||||
main()
|
main()
|
||||||
|
|||||||
@ -208,9 +208,9 @@ def render_decl(d: Definition) -> str:
|
|||||||
text += d.name
|
text += d.name
|
||||||
|
|
||||||
if d.params is not None:
|
if d.params is not None:
|
||||||
params = ", ".join([
|
params = ", ".join(
|
||||||
(p.type + " " if p.type else "") + p.name for p in d.params
|
[(p.type + " " if p.type else "") + p.name for p in d.params]
|
||||||
])
|
)
|
||||||
text += "(" + escape_html(params) + ")"
|
text += "(" + escape_html(params) + ")"
|
||||||
if d.trailing_return_type:
|
if d.trailing_return_type:
|
||||||
text += " -⁠> " + escape_html(d.trailing_return_type)
|
text += " -⁠> " + escape_html(d.trailing_return_type)
|
||||||
@ -445,7 +445,9 @@ class CxxHandler(BaseHandler):
|
|||||||
|
|
||||||
|
|
||||||
def get_handler(
|
def get_handler(
|
||||||
handler_config: "MutableMapping[str, Any]", tool_config: "MkDocsConfig", **kwargs: Any
|
handler_config: "MutableMapping[str, Any]",
|
||||||
|
tool_config: "MkDocsConfig",
|
||||||
|
**kwargs: Any,
|
||||||
) -> CxxHandler:
|
) -> CxxHandler:
|
||||||
"""Return an instance of `CxxHandler`.
|
"""Return an instance of `CxxHandler`.
|
||||||
|
|
||||||
|
|||||||
@ -10,10 +10,19 @@ obtained from https://github.com/settings/tokens.
|
|||||||
"""
|
"""
|
||||||
|
|
||||||
from __future__ import print_function
|
from __future__ import print_function
|
||||||
import datetime, docopt, errno, fileinput, json, os
|
|
||||||
import re, shutil, sys
|
import datetime
|
||||||
from subprocess import check_call
|
import errno
|
||||||
|
import fileinput
|
||||||
|
import json
|
||||||
|
import os
|
||||||
|
import re
|
||||||
|
import shutil
|
||||||
|
import sys
|
||||||
import urllib.request
|
import urllib.request
|
||||||
|
from subprocess import check_call
|
||||||
|
|
||||||
|
import docopt
|
||||||
|
|
||||||
|
|
||||||
class Git:
|
class Git:
|
||||||
@ -21,31 +30,31 @@ class Git:
|
|||||||
self.dir = dir
|
self.dir = dir
|
||||||
|
|
||||||
def call(self, method, args, **kwargs):
|
def call(self, method, args, **kwargs):
|
||||||
return check_call(['git', method] + list(args), **kwargs)
|
return check_call(["git", method] + list(args), **kwargs)
|
||||||
|
|
||||||
def add(self, *args):
|
def add(self, *args):
|
||||||
return self.call('add', args, cwd=self.dir)
|
return self.call("add", args, cwd=self.dir)
|
||||||
|
|
||||||
def checkout(self, *args):
|
def checkout(self, *args):
|
||||||
return self.call('checkout', args, cwd=self.dir)
|
return self.call("checkout", args, cwd=self.dir)
|
||||||
|
|
||||||
def clean(self, *args):
|
def clean(self, *args):
|
||||||
return self.call('clean', args, cwd=self.dir)
|
return self.call("clean", args, cwd=self.dir)
|
||||||
|
|
||||||
def clone(self, *args):
|
def clone(self, *args):
|
||||||
return self.call('clone', list(args) + [self.dir])
|
return self.call("clone", list(args) + [self.dir])
|
||||||
|
|
||||||
def commit(self, *args):
|
def commit(self, *args):
|
||||||
return self.call('commit', args, cwd=self.dir)
|
return self.call("commit", args, cwd=self.dir)
|
||||||
|
|
||||||
def pull(self, *args):
|
def pull(self, *args):
|
||||||
return self.call('pull', args, cwd=self.dir)
|
return self.call("pull", args, cwd=self.dir)
|
||||||
|
|
||||||
def push(self, *args):
|
def push(self, *args):
|
||||||
return self.call('push', args, cwd=self.dir)
|
return self.call("push", args, cwd=self.dir)
|
||||||
|
|
||||||
def reset(self, *args):
|
def reset(self, *args):
|
||||||
return self.call('reset', args, cwd=self.dir)
|
return self.call("reset", args, cwd=self.dir)
|
||||||
|
|
||||||
def update(self, *args):
|
def update(self, *args):
|
||||||
clone = not os.path.exists(self.dir)
|
clone = not os.path.exists(self.dir)
|
||||||
@ -55,8 +64,8 @@ class Git:
|
|||||||
|
|
||||||
|
|
||||||
def clean_checkout(repo, branch):
|
def clean_checkout(repo, branch):
|
||||||
repo.clean('-f', '-d')
|
repo.clean("-f", "-d")
|
||||||
repo.reset('--hard')
|
repo.reset("--hard")
|
||||||
repo.checkout(branch)
|
repo.checkout(branch)
|
||||||
|
|
||||||
|
|
||||||
@ -65,70 +74,71 @@ class Runner:
|
|||||||
self.cwd = cwd
|
self.cwd = cwd
|
||||||
|
|
||||||
def __call__(self, *args, **kwargs):
|
def __call__(self, *args, **kwargs):
|
||||||
kwargs['cwd'] = kwargs.get('cwd', self.cwd)
|
kwargs["cwd"] = kwargs.get("cwd", self.cwd)
|
||||||
check_call(args, **kwargs)
|
check_call(args, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
def create_build_env():
|
def create_build_env():
|
||||||
"""Create a build environment."""
|
"""Create a build environment."""
|
||||||
|
|
||||||
class Env:
|
class Env:
|
||||||
pass
|
pass
|
||||||
|
|
||||||
env = Env()
|
env = Env()
|
||||||
env.fmt_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
|
env.fmt_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
|
||||||
env.build_dir = 'build'
|
env.build_dir = "build"
|
||||||
env.fmt_repo = Git(os.path.join(env.build_dir, 'fmt'))
|
env.fmt_repo = Git(os.path.join(env.build_dir, "fmt"))
|
||||||
return env
|
return env
|
||||||
|
|
||||||
|
|
||||||
if __name__ == '__main__':
|
if __name__ == "__main__":
|
||||||
args = docopt.docopt(__doc__)
|
args = docopt.docopt(__doc__)
|
||||||
env = create_build_env()
|
env = create_build_env()
|
||||||
fmt_repo = env.fmt_repo
|
fmt_repo = env.fmt_repo
|
||||||
|
|
||||||
branch = args.get('<branch>')
|
branch = args.get("<branch>")
|
||||||
if branch is None:
|
if branch is None:
|
||||||
branch = 'master'
|
branch = "master"
|
||||||
if not fmt_repo.update('-b', branch, 'git@github.com:fmtlib/fmt'):
|
if not fmt_repo.update("-b", branch, "git@github.com:fmtlib/fmt"):
|
||||||
clean_checkout(fmt_repo, branch)
|
clean_checkout(fmt_repo, branch)
|
||||||
|
|
||||||
# Update the date in the changelog and extract the version and the first
|
# Update the date in the changelog and extract the version and the first
|
||||||
# section content.
|
# section content.
|
||||||
changelog = 'ChangeLog.md'
|
changelog = "ChangeLog.md"
|
||||||
changelog_path = os.path.join(fmt_repo.dir, changelog)
|
changelog_path = os.path.join(fmt_repo.dir, changelog)
|
||||||
is_first_section = True
|
is_first_section = True
|
||||||
first_section = []
|
first_section = []
|
||||||
for i, line in enumerate(fileinput.input(changelog_path, inplace=True)):
|
for i, line in enumerate(fileinput.input(changelog_path, inplace=True)):
|
||||||
if i == 0:
|
if i == 0:
|
||||||
version = re.match(r'# (.*) - TBD', line).group(1)
|
version = re.match(r"# (.*) - TBD", line).group(1)
|
||||||
line = '# {} - {}\n'.format(
|
line = "# {} - {}\n".format(version, datetime.date.today().isoformat())
|
||||||
version, datetime.date.today().isoformat())
|
|
||||||
elif not is_first_section:
|
elif not is_first_section:
|
||||||
pass
|
pass
|
||||||
elif line.startswith('#'):
|
elif line.startswith("#"):
|
||||||
is_first_section = False
|
is_first_section = False
|
||||||
else:
|
else:
|
||||||
first_section.append(line)
|
first_section.append(line)
|
||||||
sys.stdout.write(line)
|
sys.stdout.write(line)
|
||||||
if first_section[0] == '\n':
|
if first_section[0] == "\n":
|
||||||
first_section.pop(0)
|
first_section.pop(0)
|
||||||
|
|
||||||
ns_version = None
|
ns_version = None
|
||||||
base_h_path = os.path.join(fmt_repo.dir, 'include', 'fmt', 'base.h')
|
base_h_path = os.path.join(fmt_repo.dir, "include", "fmt", "base.h")
|
||||||
for line in fileinput.input(base_h_path):
|
for line in fileinput.input(base_h_path):
|
||||||
m = re.match(r'\s*inline namespace v(.*) .*', line)
|
m = re.match(r"\s*inline namespace v(.*) .*", line)
|
||||||
if m:
|
if m:
|
||||||
ns_version = m.group(1)
|
ns_version = m.group(1)
|
||||||
break
|
break
|
||||||
major_version = version.split('.')[0]
|
major_version = version.split(".")[0]
|
||||||
if not ns_version or ns_version != major_version:
|
if not ns_version or ns_version != major_version:
|
||||||
raise Exception(f'Version mismatch {ns_version} != {major_version}')
|
raise Exception(f"Version mismatch {ns_version} != {major_version}")
|
||||||
|
|
||||||
# Workaround GitHub-flavored Markdown treating newlines as <br>.
|
# Workaround GitHub-flavored Markdown treating newlines as <br>.
|
||||||
changes = ''
|
changes = ""
|
||||||
code_block = False
|
code_block = False
|
||||||
stripped = False
|
stripped = False
|
||||||
for line in first_section:
|
for line in first_section:
|
||||||
if re.match(r'^\s*```', line):
|
if re.match(r"^\s*```", line):
|
||||||
code_block = not code_block
|
code_block = not code_block
|
||||||
changes += line
|
changes += line
|
||||||
stripped = False
|
stripped = False
|
||||||
@ -136,53 +146,64 @@ if __name__ == '__main__':
|
|||||||
if code_block:
|
if code_block:
|
||||||
changes += line
|
changes += line
|
||||||
continue
|
continue
|
||||||
if line == '\n' or re.match(r'^\s*\|.*', line):
|
if line == "\n" or re.match(r"^\s*\|.*", line):
|
||||||
if stripped:
|
if stripped:
|
||||||
changes += '\n'
|
changes += "\n"
|
||||||
stripped = False
|
stripped = False
|
||||||
changes += line
|
changes += line
|
||||||
continue
|
continue
|
||||||
if stripped:
|
if stripped:
|
||||||
line = ' ' + line.lstrip()
|
line = " " + line.lstrip()
|
||||||
changes += line.rstrip()
|
changes += line.rstrip()
|
||||||
stripped = True
|
stripped = True
|
||||||
|
|
||||||
fmt_repo.checkout('-B', 'release')
|
fmt_repo.checkout("-B", "release")
|
||||||
fmt_repo.add(changelog)
|
fmt_repo.add(changelog)
|
||||||
fmt_repo.commit('-m', 'Update version')
|
fmt_repo.commit("-m", "Update version")
|
||||||
|
|
||||||
# Build the docs and package.
|
# Build the docs and package.
|
||||||
run = Runner(fmt_repo.dir)
|
run = Runner(fmt_repo.dir)
|
||||||
run('cmake', '.')
|
run("cmake", ".")
|
||||||
run('make', 'doc', 'package_source')
|
run("make", "doc", "package_source")
|
||||||
|
|
||||||
# Create a release on GitHub.
|
# Create a release on GitHub.
|
||||||
fmt_repo.push('origin', 'release')
|
fmt_repo.push("origin", "release")
|
||||||
auth_headers = {'Authorization': 'token ' + os.getenv('FMT_TOKEN')}
|
auth_headers = {"Authorization": "token " + os.getenv("FMT_TOKEN")}
|
||||||
req = urllib.request.Request(
|
req = urllib.request.Request(
|
||||||
'https://api.github.com/repos/fmtlib/fmt/releases',
|
"https://api.github.com/repos/fmtlib/fmt/releases",
|
||||||
data=json.dumps({'tag_name': version,
|
data=json.dumps(
|
||||||
'target_commitish': 'release',
|
{
|
||||||
'body': changes, 'draft': True}).encode('utf-8'),
|
"tag_name": version,
|
||||||
headers=auth_headers, method='POST')
|
"target_commitish": "release",
|
||||||
|
"body": changes,
|
||||||
|
"draft": True,
|
||||||
|
}
|
||||||
|
).encode("utf-8"),
|
||||||
|
headers=auth_headers,
|
||||||
|
method="POST",
|
||||||
|
)
|
||||||
with urllib.request.urlopen(req) as response:
|
with urllib.request.urlopen(req) as response:
|
||||||
if response.status != 201:
|
if response.status != 201:
|
||||||
raise Exception(f'Failed to create a release ' +
|
raise Exception(
|
||||||
'{response.status} {response.reason}')
|
f"Failed to create a release " + "{response.status} {response.reason}"
|
||||||
response_data = json.loads(response.read().decode('utf-8'))
|
)
|
||||||
id = response_data['id']
|
response_data = json.loads(response.read().decode("utf-8"))
|
||||||
|
id = response_data["id"]
|
||||||
|
|
||||||
# Upload the package.
|
# Upload the package.
|
||||||
uploads_url = 'https://uploads.github.com/repos/fmtlib/fmt/releases'
|
uploads_url = "https://uploads.github.com/repos/fmtlib/fmt/releases"
|
||||||
package = 'fmt-{}.zip'.format(version)
|
package = "fmt-{}.zip".format(version)
|
||||||
req = urllib.request.Request(
|
req = urllib.request.Request(
|
||||||
f'{uploads_url}/{id}/assets?name={package}',
|
f"{uploads_url}/{id}/assets?name={package}",
|
||||||
headers={'Content-Type': 'application/zip'} | auth_headers,
|
headers={"Content-Type": "application/zip"} | auth_headers,
|
||||||
data=open('build/fmt/' + package, 'rb').read(), method='POST')
|
data=open("build/fmt/" + package, "rb").read(),
|
||||||
|
method="POST",
|
||||||
|
)
|
||||||
with urllib.request.urlopen(req) as response:
|
with urllib.request.urlopen(req) as response:
|
||||||
if response.status != 201:
|
if response.status != 201:
|
||||||
raise Exception(f'Failed to upload an asset '
|
raise Exception(
|
||||||
'{response.status} {response.reason}')
|
f"Failed to upload an asset " "{response.status} {response.reason}"
|
||||||
|
)
|
||||||
|
|
||||||
short_version = '.'.join(version.split('.')[:-1])
|
short_version = ".".join(version.split(".")[:-1])
|
||||||
check_call(['./mkdocs', 'deploy', short_version])
|
check_call(["./mkdocs", "deploy", short_version])
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user